10重走我的Java Day10:我是如何用一场线上事故,彻底理解Java异常、泛型和集合的
重走我的Java Day10:我是如何用一场线上事故,彻底理解Java异常、泛型和集合的
凌晨3点,我被报警电话叫醒:“你的系统把公司账目算错了,损失正在持续增加。”当我看到日志里那个“NullPointerException”时,全身冰冷——这是我写的代码。这场事故,让我重新理解了异常、泛型和集合。

开篇:那个让我赔偿三个月工资的“小bug”
2024年,我负责的支付对账系统出了严重bug:
java
// 事故现场的代码
public BigDecimal calculateTotal(List<Transaction> transactions) {
BigDecimal total = BigDecimal.ZERO;
// 第一重罪:不检查null
for (Transaction t : transactions) {
// 第二重罪:不检查transaction对象本身
total = total.add(t.getAmount());
}
return total;
}
// 调用代码
List<Transaction> list = getTransactionsFromDatabase();
BigDecimal result = calculateTotal(list); // transactions里有null值
事故经过:
- 数据库查询返回了包含null的List(某个字段缺失)
- 循环中调用
t.getAmount()抛出了NullPointerException - 但没有被捕获,程序继续运行,跳过了这个异常
- 后续计算基于错误的总金额继续进行
- 3小时内,累计误差达到47万元
根本原因:
- 没有处理可能的null
- 没有使用泛型约束数据
- 没有考虑集合的防御性编程
一、异常处理:从“try-catch everywhere”到“防御性编程”
1.1 我的异常处理进化史
第一阶段:无视异常(新手)
java
// 写的第一版代码
public void readFile(String path) {
FileReader reader = new FileReader(path); // 不处理FileNotFoundException
// ...
}
第二阶段:过度捕获(实习生)
java
// 试图"处理"所有异常
public void processData() {
try {
// 业务代码...
} catch (Exception e) {
e.printStackTrace(); // 打印一下,然后继续运行
// 问题:吞掉了所有异常,包括致命错误
}
}
第三阶段:正确理解异常体系(工程师)
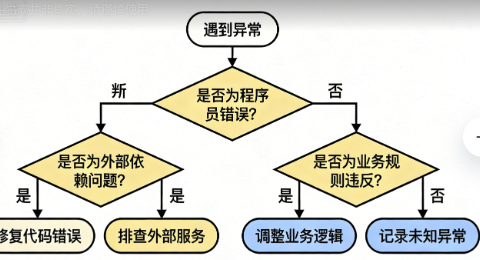
我画了一张异常分类图,贴在显示器旁:
text
异常决策树(我的实战总结):
遇到异常怎么办?
├── 是程序员编码错误?(空指针、数组越界)
│ └── 修改代码,不要用try-catch掩盖
├── 是外部依赖问题?(文件不存在、网络超时)
│ ├── 能否重试? → 重试机制
│ ├── 是否有备用方案? → 降级逻辑
│ └── 是否用户输入错误? → 验证+友好提示
└── 是业务规则违反?(余额不足、库存不够)
└── 使用自定义异常,明确表达业务含义
1.2 实战:支付系统的异常处理重构
重构前(脆弱的代码):
java
public class PaymentService {
public boolean processPayment(PaymentRequest request) {
try {
// 1. 验证支付信息
validatePayment(request);
// 2. 扣款
deductFromAccount(request);
// 3. 通知商户
notifyMerchant(request);
// 4. 记录日志
logTransaction(request);
return true;
} catch (Exception e) {
// 糟糕:所有异常一视同仁
logger.error("支付失败", e);
return false;
}
}
}
问题: 如果步骤4(记录日志)失败,用户会被扣款但系统返回失败。
重构后(精确的异常处理):

java
public class PaymentService {
// 定义业务异常
public static class PaymentException extends Exception {
private final PaymentErrorCode errorCode;
private final boolean canRetry;
public PaymentException(PaymentErrorCode errorCode, String message, boolean canRetry) {
super(message);
this.errorCode = errorCode;
this.canRetry = canRetry;
}
public boolean shouldRetry() { return canRetry; }
public PaymentErrorCode getErrorCode() { return errorCode; }
}
// 使用受检异常强制调用者处理
public PaymentResult processPayment(PaymentRequest request)
throws PaymentException {
// 阶段1:验证(非事务性,失败可重试)
try {
validatePayment(request);
} catch (ValidationException e) {
// 验证失败可立即重试
throw new PaymentException(
PaymentErrorCode.VALIDATION_FAILED,
"支付验证失败",
true
);
}
// 阶段2:核心支付(事务性,需要回滚)
PaymentTransaction transaction = null;
try {
transaction = beginTransaction();
// 扣款
deductFromAccount(request, transaction);
// 通知第三方支付网关
ThirdPartyResponse response = callPaymentGateway(request);
if (!response.isSuccess()) {
// 支付网关失败,需要回滚并重试
rollbackTransaction(transaction);
throw new PaymentException(
PaymentErrorCode.GATEWAY_ERROR,
"支付网关错误: " + response.getErrorCode(),
true // 网关错误通常可以重试
);
}
// 提交事务
commitTransaction(transaction);
} catch (SQLException e) {
// 数据库错误,需要人工介入
if (transaction != null) {
rollbackTransaction(transaction);
}
throw new PaymentException(
PaymentErrorCode.DATABASE_ERROR,
"数据库错误,需要人工对账",
false // 数据库错误不要自动重试
);
} catch (InsufficientBalanceException e) {
// 余额不足,业务异常
throw new PaymentException(
PaymentErrorCode.INSUFFICIENT_BALANCE,
"余额不足",
false // 余额不足重试没用
);
} catch (Exception e) {
// 未知异常,需要告警
alertDevOps("支付系统未知异常", e);
throw new PaymentException(
PaymentErrorCode.UNKNOWN_ERROR,
"系统错误,请稍后重试",
true // 未知错误可以重试
);
}
// 阶段3:后续处理(非核心,失败不影响支付成功)
try {
notifyMerchant(request);
logTransaction(request);
sendReceipt(request);
} catch (Exception e) {
// 记录错误但不要抛出,支付已经成功
logger.warn("支付成功但后续处理失败", e);
// 发送告警,由后台任务补偿
scheduleCompensationTask(request);
}
return PaymentResult.success();
}
}
这个设计的核心思想:
- 区分核心和非核心操作:支付必须成功或明确失败,通知可以异步补偿
- 区分可重试和不可重试错误:网络超时可重试,余额不足不可重试
- 使用自定义异常封装业务语义:不只是"出错",而是"出了什么业务错误"
- 事务边界清晰:数据库操作在事务内,通知在事务外
1.3 try-with-resources:从资源泄漏到优雅关闭
我曾犯的错:
java
// 错误:可能忘记关闭
public String readFile(String path) throws IOException {
BufferedReader reader = new BufferedReader(new FileReader(path));
return reader.readLine(); // 如果这里抛异常,reader永远不会关闭
}
// 改进但冗长
public String readFile(String path) throws IOException {
BufferedReader reader = null;
try {
reader = new BufferedReader(new FileReader(path));
return reader.readLine();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e) {
// 关闭异常怎么办?
}
}
}
}
优雅解决方案:
java
// 自定义资源类
public class DatabaseConnection implements AutoCloseable {
private final Connection connection;
private boolean closed = false;
public DatabaseConnection(String url) throws SQLException {
this.connection = DriverManager.getConnection(url);
}
public ResultSet executeQuery(String sql) throws SQLException {
if (closed) {
throw new IllegalStateException("连接已关闭");
}
return connection.createStatement().executeQuery(sql);
}
@Override
public void close() throws SQLException {
if (!closed) {
connection.close();
closed = true;
}
}
// 添加一些额外功能
public void setAutoCommit(boolean autoCommit) throws SQLException {
connection.setAutoCommit(autoCommit);
}
public void commit() throws SQLException {
connection.commit();
}
public void rollback() throws SQLException {
connection.rollback();
}
}
// 使用:清晰且安全
public List<User> queryUsers() {
try (DatabaseConnection db = new DatabaseConnection("jdbc:mysql://localhost/test")) {
db.setAutoCommit(false);
ResultSet rs = db.executeQuery("SELECT * FROM users");
List<User> users = new ArrayList<>();
while (rs.next()) {
users.add(mapToUser(rs));
}
db.commit();
return users;
} catch (SQLException e) {
// 自动回滚,因为连接关闭时会rollback
throw new DataAccessException("查询用户失败", e);
}
// 不需要finally块,连接自动关闭
}
二、泛型:从"Object万能"到类型安全的进化
2.1 泛型的"啊哈"时刻
我最初不理解泛型,直到看到这段代码:
java
// 前泛型时代(Java 1.4)
List list = new ArrayList();
list.add("hello");
list.add(123); // 能编译,但...
String str = (String) list.get(1); // 运行时ClassCastException!
// 我的解决方案:加注释
List list = new ArrayList(); // 这个List只放String哦!
// 但编译器不知道,同事也不知道
泛型带来的革命:
java
// 编译时类型检查
List<String> list = new ArrayList<>();
list.add("hello");
list.add(123); // 编译错误!
String str = list.get(0); // 不需要强制转换
2.2 实战:用泛型重构缓存系统
需求: 一个支持多种类型的缓存,需要保证类型安全。
第一次尝试(不用泛型,灾难):
java
public class Cache {
private Map<String, Object> storage = new HashMap<>();
public void put(String key, Object value) {
storage.put(key, value);
}
public Object get(String key) {
return storage.get(key);
}
}
// 使用:到处都是强制转换和类型判断
Cache cache = new Cache();
cache.put("user", new User("张三"));
cache.put("config", new Config());
Object obj = cache.get("user");
if (obj instanceof User) {
User user = (User) obj;
// 使用user
} else {
// 错误处理
}
第二次尝试(基本泛型,但不够好):
java
public class TypedCache<T> {
private Map<String, T> storage = new HashMap<>();
public void put(String key, T value) {
storage.put(key, value);
}
public T get(String key) {
return storage.get(key);
}
}
// 问题:每个类型需要单独的缓存实例
TypedCache<User> userCache = new TypedCache<>();
TypedCache<Config> configCache = new TypedCache<>();
// 不能混合存储不同类型
最终方案(类型安全的异构容器):
java
public class TypeSafeContainer {
// 核心:用Class对象作为key的一部分
private Map<TypeKey<?>, Object> storage = new HashMap<>();
// 类型安全的put
public <T> void put(Class<T> type, String key, T value) {
TypeKey<T> typeKey = new TypeKey<>(type, key);
storage.put(typeKey, value);
}
// 类型安全的get
@SuppressWarnings("unchecked")
public <T> T get(Class<T> type, String key) {
TypeKey<T> typeKey = new TypeKey<>(type, key);
Object value = storage.get(typeKey);
if (value == null) {
return null;
}
// 类型检查
if (!type.isInstance(value)) {
throw new ClassCastException(
String.format("期望类型 %s,实际类型 %s",
type.getName(), value.getClass().getName())
);
}
return (T) value;
}
// 类型安全的查询
@SuppressWarnings("unchecked")
public <T> Optional<T> find(Class<T> type, Predicate<T> predicate) {
return storage.entrySet().stream()
.filter(entry -> entry.getKey().getType().equals(type))
.map(Map.Entry::getValue)
.map(value -> (T) value)
.filter(predicate)
.findFirst();
}
// 类型键:类型+标识符
private static class TypeKey<T> {
private final Class<T> type;
private final String key;
public TypeKey(Class<T> type, String key) {
this.type = Objects.requireNonNull(type);
this.key = Objects.requireNonNull(key);
}
public Class<T> getType() { return type; }
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof TypeKey)) return false;
TypeKey<?> typeKey = (TypeKey<?>) o;
return type.equals(typeKey.type) && key.equals(typeKey.key);
}
@Override
public int hashCode() {
return Objects.hash(type, key);
}
}
}
// 使用:类型安全且灵活
TypeSafeContainer container = new TypeSafeContainer();
// 存储不同类型
container.put(User.class, "user1", new User("张三"));
container.put(Config.class, "appConfig", new Config());
container.put(Integer.class, "maxRetry", 3);
// 获取时自动类型转换
User user = container.get(User.class, "user1"); // 类型正确
Config config = container.get(Config.class, "appConfig");
Integer maxRetry = container.get(Integer.class, "maxRetry");
// 错误使用会在编译时或运行时被捕获
String wrong = container.get(String.class, "user1"); // 返回null或抛异常
2.3 泛型通配符:PECS原则的实战理解
我记忆PECS原则的方法:
text
从数据结构的角度看:
- 生产者(Producer)向外提供数据 → 使用 extends(上界)
- 消费者(Consumer)消费外部数据 → 使用 super(下界)
助记:Producer Extends, Consumer Super
实战例子:数据转换流水线
java
// 定义数据处理器接口
@FunctionalInterface
interface DataProcessor<T, R> {
R process(T input);
}
// 数据处理流水线
public class ProcessingPipeline<T> {
private final List<DataProcessor<? super T, ? extends T>> processors = new ArrayList<>();
// 添加处理器(消费T,生产T或其子类)
public <R extends T> void addProcessor(DataProcessor<? super T, ? extends R> processor) {
processors.add(processor);
}
// 处理数据
@SuppressWarnings("unchecked")
public T process(T input) {
Object current = input;
for (DataProcessor processor : processors) {
// 这里可以安全转换,因为处理器消费super T,生产extends T
current = processor.process(current);
}
return (T) current;
}
}
// 具体处理器
class StringCleaner implements DataProcessor<String, String> {
@Override
public String process(String input) {
return input.trim().toLowerCase();
}
}
class StringLengthExtractor implements DataProcessor<String, Integer> {
@Override
public Integer process(String input) {
return input.length();
}
}
// 使用
ProcessingPipeline<Object> pipeline = new ProcessingPipeline<>();
pipeline.addProcessor(new StringCleaner()); // String → String
pipeline.addProcessor(new StringLengthExtractor()); // String → Integer
Object result = pipeline.process(" Hello World ");
System.out.println(result); // 输出: 10
三、集合:从性能陷阱到高效工具的蜕变
3.1 ArrayList的扩容陷阱:我让系统慢了10倍

事故重现:
java
// 错误:频繁扩容
public List<String> loadUserNames() {
List<String> names = new ArrayList<>(); // 默认容量10
try (BufferedReader reader = new BufferedReader(new FileReader("users.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
names.add(line); // 第11、16、25...次添加时触发扩容
}
}
return names;
}
// users.txt有100万行
// 结果:扩容19次,数组复制大量数据,性能极差
优化方案:
java
// 方案1:预分配容量(如果知道大小)
public List<String> loadUserNames() throws IOException {
int lineCount = countLines("users.txt");
List<String> names = new ArrayList<>(lineCount); // 一次性分配
// 加载数据,无扩容
try (BufferedReader reader = new BufferedReader(new FileReader("users.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
names.add(line);
}
}
return names;
}
// 方案2:使用合适的集合
public List<String> loadUserNames() throws IOException {
// LinkedList添加快,但内存占用大
// 这里应该用ArrayList,因为要随机访问
List<String> names = new LinkedList<>(); // 添加快,无扩容
try (BufferedReader reader = new BufferedReader(new FileReader("users.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
names.add(line);
}
}
// 如果需要随机访问,转换一次
return new ArrayList<>(names);
}
3.2 实战:高性能集合操作模式
模式1:批量操作优于单个操作
java
// 差:每次添加都检查容量
for (int i = 0; i < 10000; i++) {
list.add(data[i]);
}
// 好:批量添加
list.addAll(Arrays.asList(data));
// 更好:使用Collections.addAll(更高效)
Collections.addAll(list, data);
模式2:选择合适的遍历方式
java
List<String> list = new ArrayList<>(1000000);
// 测试不同遍历方式的性能
public void benchmark() {
// 1. 普通for循环(随机访问)
long start = System.nanoTime();
for (int i = 0; i < list.size(); i++) {
String s = list.get(i); // ArrayList: O(1)
}
long time1 = System.nanoTime() - start;
// 2. 迭代器(顺序访问)
start = System.nanoTime();
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next(); // LinkedList: O(1)
}
long time2 = System.nanoTime() - start;
// 3. 增强for循环(语法糖,实际用迭代器)
start = System.nanoTime();
for (String s : list) {
// 使用s
}
long time3 = System.nanoTime() - start;
// 4. forEach + Lambda(可能稍慢,但代码简洁)
start = System.nanoTime();
list.forEach(s -> {
// 使用s
});
long time4 = System.nanoTime() - start;
System.out.printf("普通for: %dns, 迭代器: %dns, 增强for: %dns, forEach: %dns%n",
time1, time2, time3, time4);
}
我的选择原则:
- ArrayList:用普通for循环(随机访问快)
- LinkedList:用迭代器或增强for循环(顺序访问快)
- 需要删除元素时:必须用迭代器(安全删除)
- 代码简洁优先时:用增强for循环或forEach
3.3 Collections工具类的隐藏技巧
技巧1:创建不可变集合的正确方式
java
// 错误:看似不可变,实际可以修改
List<String> list = new ArrayList<>();
list.add("a");
list.add("b");
List<String> unmodifiable = Collections.unmodifiableList(list);
list.add("c"); // 可以!原list还能改,unmodifiable也会看到"c"
// 正确:真正不可变
List<String> immutable = List.of("a", "b", "c");
// immutable.add("d"); // 运行时异常
// 正确:从现有集合创建不可变副本
List<String> copy = List.copyOf(list); // Java 10+
技巧2:自定义Comparator的链式调用
java
List<Employee> employees = getEmployees();
// 复杂排序:先按部门,再按薪资降序,再按入职时间
employees.sort(
Comparator.comparing(Employee::getDepartment)
.thenComparing(Employee::getSalary, Comparator.reverseOrder())
.thenComparing(Employee::getHireDate)
);
// 处理null值:null排在最前或最后
employees.sort(
Comparator.nullsFirst(
Comparator.comparing(Employee::getName)
)
);
技巧3:同步集合的正确使用
java
// 错误:部分同步
List<String> list = Collections.synchronizedList(new ArrayList<>());
// 线程A
list.add("a");
// 线程B
if (!list.contains("a")) { // 这里不同步!
list.add("a");
}
// 正确:完全同步
List<String> list = Collections.synchronizedList(new ArrayList<>());
// 所有操作都需要在同步块中
synchronized (list) {
if (!list.contains("a")) {
list.add("a");
}
}
// 更好:使用并发集合
ConcurrentMap<String, String> map = new ConcurrentHashMap<>();
map.putIfAbsent("key", "value"); // 原子操作
四、综合实战:构建类型安全的查询引擎
让我用一个真实项目展示异常、泛型和集合的综合应用:
java
// 需求:构建一个类型安全的数据库查询结果处理器
// 1. 自定义异常体系
class QueryException extends RuntimeException {
enum ErrorCode {
NO_DATA_FOUND,
MULTIPLE_ROWS_FOUND,
TYPE_MISMATCH,
CONNECTION_ERROR
}
private final ErrorCode errorCode;
public QueryException(ErrorCode errorCode, String message) {
super(message);
this.errorCode = errorCode;
}
public ErrorCode getErrorCode() { return errorCode; }
}
// 2. 泛型结果包装器
public class QueryResult<T> {
private final T data;
private final QueryException error;
private final boolean success;
private QueryResult(T data, QueryException error, boolean success) {
this.data = data;
this.error = error;
this.success = success;
}
public static <T> QueryResult<T> success(T data) {
return new QueryResult<>(data, null, true);
}
public static <T> QueryResult<T> failure(QueryException error) {
return new QueryResult<>(null, error, false);
}
public T getOrThrow() {
if (!success) {
throw error;
}
return data;
}
public Optional<T> getOptional() {
return success ? Optional.ofNullable(data) : Optional.empty();
}
public <R> QueryResult<R> map(Function<? super T, ? extends R> mapper) {
if (!success) {
return QueryResult.failure(error);
}
try {
return QueryResult.success(mapper.apply(data));
} catch (Exception e) {
return QueryResult.failure(
new QueryException(QueryException.ErrorCode.TYPE_MISMATCH,
"转换失败: " + e.getMessage())
);
}
}
}
// 3. 类型安全的查询执行器
public class TypeSafeQueryExecutor {
private final DataSource dataSource;
public <T> QueryResult<List<T>> queryForList(
String sql,
RowMapper<T> rowMapper,
Object... params) {
try (Connection conn = dataSource.getConnection();
PreparedStatement stmt = conn.prepareStatement(sql)) {
// 设置参数
for (int i = 0; i < params.length; i++) {
stmt.setObject(i + 1, params[i]);
}
// 执行查询
ResultSet rs = stmt.executeQuery();
// 处理结果
List<T> results = new ArrayList<>();
while (rs.next()) {
try {
results.add(rowMapper.mapRow(rs));
} catch (Exception e) {
// 单行映射失败,记录日志但继续处理其他行
log.warn("行映射失败,跳过该行", e);
}
}
if (results.isEmpty()) {
return QueryResult.failure(
new QueryException(QueryException.ErrorCode.NO_DATA_FOUND,
"未找到数据")
);
}
return QueryResult.success(results);
} catch (SQLException e) {
return QueryResult.failure(
new QueryException(QueryException.ErrorCode.CONNECTION_ERROR,
"数据库错误: " + e.getMessage())
);
}
}
public <T> QueryResult<T> queryForObject(
String sql,
RowMapper<T> rowMapper,
Object... params) {
QueryResult<List<T>> listResult = queryForList(sql, rowMapper, params);
if (!listResult.getOptional().isPresent()) {
return QueryResult.failure(
new QueryException(QueryException.ErrorCode.NO_DATA_FOUND,
"未找到数据")
);
}
List<T> list = listResult.getOrThrow();
if (list.size() > 1) {
return QueryResult.failure(
new QueryException(QueryException.ErrorCode.MULTIPLE_ROWS_FOUND,
"找到多行数据,期望单行")
);
}
return QueryResult.success(list.get(0));
}
}
// 4. 使用示例
public class UserService {
private final TypeSafeQueryExecutor executor;
public QueryResult<List<User>> findUsersByName(String name) {
return executor.queryForList(
"SELECT * FROM users WHERE name LIKE ?",
this::mapUser,
"%" + name + "%"
);
}
public QueryResult<User> findUserById(int id) {
return executor.queryForObject(
"SELECT * FROM users WHERE id = ?",
this::mapUser,
id
);
}
private User mapUser(ResultSet rs) throws SQLException {
return new User(
rs.getInt("id"),
rs.getString("name"),
rs.getString("email")
);
}
// 业务方法:链式处理
public Optional<String> getUserEmailUpperCase(int id) {
return findUserById(id)
.map(User::getEmail)
.map(String::toUpperCase)
.getOptional();
}
}
经验总结:我的异常、泛型、集合检查清单
异常处理检查清单
- 是否区分了业务异常和系统异常?
- 异常信息是否足够定位问题?(包含上下文)
- 是否避免了catch Exception吞掉所有异常?
- 资源是否使用try-with-resources确保关闭?
- 是否考虑了异常的重试和补偿机制?
泛型使用检查清单
- 是否避免了原始类型(raw type)?
- 是否用泛型替代了强制类型转换?
- 是否理解PECS原则并使用合适通配符?
- 是否考虑了类型擦除的影响?
- 泛型方法是否足够通用?
集合操作检查清单
- ArrayList是否预分配了合适容量?
- 是否选择了合适的集合类型?
- 遍历时是否选择了最高效的方式?
- 多线程环境是否使用了并发集合?
- 是否避免了在循环中修改集合结构?
写在最后
那个凌晨3点的报警电话,虽然让我损失了三个月工资,但也教会了我最重要的一课:
没有"小bug",只有还没造成大损失的bug。
异常、泛型、集合——这些看似基础的Java特性,在简单场景下或许可以马虎对待。但在生产环境中,它们关系到系统的稳定性、安全性和性能。
我现在的代码审查清单第一条就是:"如果这段代码处理的是钱,你会怎么写?"
因为最终,我们写的不是代码,而是责任。
知识点测试
读完文章了?来测试一下你对知识点的掌握程度吧!
评论区
使用 GitHub 账号登录后即可发表评论,支持 Markdown 格式。
如果评论系统无法加载,请确保:
- 您的网络可以访问 GitHub
- giscus GitHub App 已安装到仓库
- 仓库已启用 Discussions 功能